SVM (Support Vector Machine)
SVM (Support Vector Machine)
SVM bekerja dengan baik pada set data dengan dimensi yang tinggi, bahkan SVM yang menggunakan teknik kernel harus memetakan data asli dari dimensi asalnya menjadi dimensi lain yang relatif lebih tinggi. Pada SVM hanya sejumlah data terpilih saja yang berkontribusi untuk membentuk model yang digunakan dalam klasifikasi yang akan dipelajari. Dan SVM hanya menyimpan sebagian data kecil saja dari data latih yang digunakan pada saat prediksi. Sehingga tidak semua data latih yang dilibatkan dalam setiap iterasi pelatihannya. Data-data yang berkontribusi tersebut disebut Support Vector sehingga metodenya juga disebut Support Vector Machine.
Konsep SVM
Ide dasar dari SVM adalah memaksimalkan batas Hyperlane, yang di ilustrasikan pada gambar dibawah ini. Pada gambar (a) ada sejumlah pilihan Hyperlane yang mungkin untuk set data, sedangkan gambar (b) merupakan Hyperlane dengan margin yang paling maksimal.
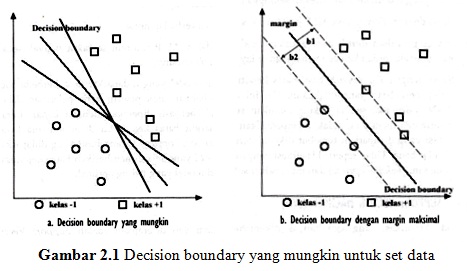
Konsep klasifikasi dengan SVM dapat dijelaskan secara sederhana sebagai usaha mencari Hyperlane terbaik yang berfungsi sebagai pemisah duah buah kelas data pada input space (Nugroho, 2007). Gambar diatas memperlihatkan beberapa data yang merupakan anggota dari dua buah kelas data yaitu +1 dan -1. Data yang tergabung pada kelas -1 disimbolkan dengan bentuk lingkaran, sedangkan data pada kelas +1 disimbolkan dengan bentuk bujur sangkar.
Hyperlane (batas keputusan) pemisah terbaik antara dua kelas dapat ditemukan dengan mengukur margin Hyperlane tersebut dan mencari titik maksimalnya. Margin adalah jarak antara Hyperlane dengan data terdekat dari masing-masing kelas. Data yang paling dekat disebut sebagai Support Vector. Garis solid pada gambar diatas (b) menunjukan Hyperlane yang terbaik, yaitu terletak tepat pada tengah-tengah kedua kelas, sedangkan data lingkaran dan bujur sangkar yang melewati garis batas margin (garis putus-putus) adalah Support Vector. Usaha untuk mencari lokasi Hyperlane ini merupakan inti dari proses pelatihan pada SVM.
SVM Nonlinear
SVM terdapat Linear dan Nonlinear (kernel trick). Seperti halnya perceptron, SVM sebenarnya adalah Hyperline liear yang hanya bekerja pada data yang dapat dipisahkan secara linear. Untuk data yang distribusi kelasnya nonlinear biasanya menggundakan pendekatan kernel pada fitur data awal set data. Kernel dapat didefinisikan sebagai suatu fungsi yang memetakan fitur data dari dimensi awal(rendah) ke fitur baru dengan dimensi yang relatif lebih tinggi (bahkan jauh lebih tinggi). Pendekatan ini berbeda dengan metode klasifikasi pada umumnya yang justru mengurangi dimensi awal untuk menyederhanakan proses komputasi dan memberikan akurasi prediksi yang lebih baik.
Berikut beberapa pilihan fungsi kernel yang banyak digunakan dalam aplikasi :
- Linear
- Polynomial
- Gaussian RBF
- Sigmoid (Tangen Hiperbolik)
- Invers Multiquadric
SVM Multikelas
Metode klasifikasi seperti Decision Tree, Artificial Neural Network, Nearest Neighbor didesain untuk dapat melakukan klasifikasi multikelas sekaligus. tetapi SVM tidak. SVM hanya dapat melakukan klasifikasi biner (2 kelas). Sementara didalam kenyataan umumnya mempunyai banyak kelas seperti pengenalan karakter, pengenalan wajah, atau diagnosis pasien dimana data masukan terbagi menjadi lebih dari dua kelas. Ada beberapa pendekatan SVM multikelas yaitu one-against-all, one-against-one, dan error correcting ouput code.
Sumber : Buku Data Mining Mengolah data menjadi informasi menggunakan MATLAB. Eko Prasetyo
Let me know what you think of this article in the comment section below!